Devoxx Poland 2018
Devoxx Poland takes place in the beautiful city of Krakow at the end of June. I attended the conference last year and really enjoyed it. Devoxx Poland offers a lot of excellent technical content, has a great venue and offers a chance to connect with industry leaders in a way only a Devoxx event can. In my opinion, it is one of the best technology conferences of the year.
Thinking Architecturally - Nate Schutta
Thinking Architecturally: Lead Technical Change Within Your Engineering Team is a free ebook available from Pivotal. The author of the book, Nate Schutta, delivered a really great presentation on architecture. He started his talk by comparing the evolution of technology with a feature, not a bug. Predicting what technology will become popular in five years time is not possible, but it is possible to evaluate technology and make good decisions on what to adopt. He claimed that, in general, developers have a fear of what is old and always want to be on the bleeding edge. However, being on the bleeding edge, means you will bleed. This resonates nicely with my talk on innovation. The reason most developers are eager to use new technology, is because learning is never boring. Since the main responsibility of developers is to deliver business value, a strategy is needed to avoid dead platforms.
Hope is not a strategy.
Nate recommended using the Thoughtworks Technology Radar to stay up to date on new technology. Another option are ‘Innovation Fridays’ or internal presentations at a customer or employer. By formally taking time for R&D, it frees everybody from chasing the new shiny like a dog chases a squirrel. In-turn this frees up time to work on business value and to focus on the problem at hand.
Every technology has trade-offs. To make conscious decisions, Nate suggested weighing technology on a number of fixed criteria. Defining these criteria can unfortunately be very hard.
You haven’t mastered a tool until you understand when it should not be used.
Nate went on to pitch the fitness functions, that are discussed in-depth in Building Evolutionary Architectures. Personally, I’m a bit skeptical about these fitness functions, particularly because I’m afraid maintaining them will be very time-consuming and because I’m unsure whether they actually add value. I will move the book up on my reading list to learn more about them, though.
CQRS and EventSourcing with Spring & Axon - Nakul Mishra
Nakul started with an introduction on domain-driven design, event sourcing and CQRS:
Four characteristics of domain-driven design:
- Place behaviour in the domain model
- Code should reflect business reality (Ubiquitous language)
- Provide a unit of consistency across domain models via aggregates
- An aggregate represents a group of objects that belong together
- Define clear bounded contexts and protect the domain model
In Event Sourcing, every event (and its state) is stored in an event store. An event store needs to:
- Append new events fast
- Verify the sequence when writing events to the event store
- Offer fast access to events (eg. for replaying)
To meet these requirements, using a purpose-built event store like AxonDB is recommended. While it is not impossible to use a relational database as an event store, it will be less then ideal.
An (additional) benefit of using event sourcing is the possibility to use all the stored events for machine learning, where individual events can be used to predict behaviour.
CQRS offers an optimization for the Pareto principle with a separation of the command and query side. More information on CQRS can be found in my blog post from SATURN.
Nakul demoed a simple application showing the core concepts mentioned earlier, using the Axon Framework and Kotlin. If you want to learn more about event sourcing or the Axon Framework, I recommended having a look at the source code of his demo application.
After the demo, he continued with event storming and his positive experience with it. He sees event storming as a collective learning experience, where the result (a wall with lots of sticky notes on it) can be used as input for engineers. Event storming will only be really successful, if the client is also commited. In my experience, this in itself can be a considerable challenge.
Modules or Microservices? - Sander Mak
For the last couple of years everybody is talking about microservices, but there are alternatives, like modules.
Both systems created using microservices and modular monoliths have their merits. Choosing the right approach is essential to achieve maintainable, extensible and reliable software.
Sander identified three tenets of modularity:
- Strong encapsulation (being able to hide the implementation details)
- Well-defined interfaces
- Explicit dependencies
Microservices embrace these tenets and also offer a solution for scaling and resilience. But microservices also have downsides, like having to deal with versioning, configuration management, service discovery, etc. Microservices are hard and limit the focus on business capability.
As an alternative, modules can be used. These also embrace the key characteristics of modularity, but without the additional complexity of a distributed system. A modular application can have the same design approach as a system composed of microservices, without the network boundaries.
Advantages of microservices:
- Choice of technology stack
- This also introduces complexity
- Independent deployment
- Beware of deployment dependencies
- Independent failure
- Requires autonomous microservices
- Independent scaling
- Monoliths can also scale
Advantages of modules
- Ease of deployment and management
- Strong but refactorable boundaries
- Strongly typed, in-process communication
- No serialization latency
- Eventual consistency is a choice
- Explicit dependencies means less runtime dependencies
Sander recommends starting with modules, but design the system like a distributed system. It remains possible to extract microservices from the monolith at a later time.
More on this topic can found here.
Reactive Webservices - Kamil Szymański
The talk on reactive webservices was a code-only talk to explain concepts like concurrency, non-blocking resources and backpressure. Spring Reactor was used to demonstrate these concepts. The first code sample, showed a blocking method and was used to measure the number of transactions per second (TPS). Using worker threads and the Callable interface, we could see an immediate impact on the TPS with small code changes. Using these easy wins, has some constraints and drawbacks, like the lack of control over the used threads.
To overcome these constraints, Spring Webflux was used. More on Mono and Flux can be found in this blog post.
A large challenge, when it comes to reactive services, are database transactions. Because a non-blocking JDBC API is not available (yet), we need to revert to older database techniques like cursors and the specific use of ResultSets and Connections. In the last couple of years these implementation details have often been abstracted away by the use of libraries like Spring Data or HibernateTemple.
Istio: Service Mesh & Dark Canaries - Edson Yanaga & Rafael Benevides
A service mesh is a dedicated infrastructure layer for handling service-to-service communication. It’s responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud native application. In practice, the service mesh is typically implemented as an array of lightweight network proxies that are deployed alongside application code, without the application needing to be aware.
In the past, we needed to implement many different tools to make use of capabilities needed for distributed systems. Many of these tools were provided by Netflix OSS and could be implemented by the service programmer. Netflix OSS is only available for Java applications and adds a lot of libraries to the service implementation. An orchestration platform, like Kubernetes has some of these capabilities built-in. For example service discovery, elasticity, … are available from the Kubernetes platform. OpenShift, which is built on Kubernetes, offers even more capabilities out of the box. Finally, with services meshes, capabilities like (mutual) authentication, tracing, … effectively become platform capabilities. In a way service meshes are comparable with aspect-oriented techniques, where certain functionality is abstracted away from the implementation.
Istio is a service mesh that provides cross-cutting functions that all micro services environments need.
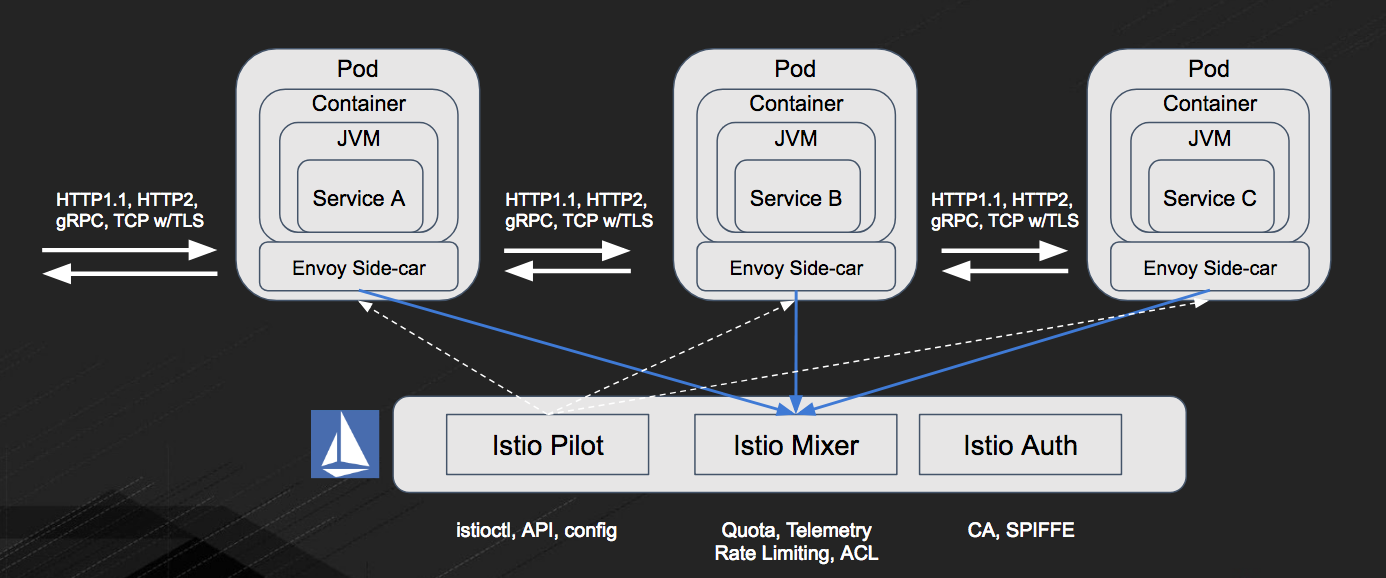
To do this, Istio uses Envoy proxies in sidecar containers that sit alongside services.
All network traffic (HTTP, REST, gRPC, Redis, etc.) from an individual service instance flows via its local sidecar proxy to the appropriate destination. Thus, the service instance is not aware of the network at large and only knows about its local proxy. In effect, the distributed system network has been abstracted away from the service programmer.
Envoy is the data plane layer of Istio. The data plane performs tasks like service discovery, health checking, routing, load balancing, authentication, authorization and observability (statistics, logging and tracing).
Istio also comes with a control plane, which is called Pilot. The control plane takes a set of isolated stateless sidecar proxies and turns them into a distributed system. Pilot controls Envoy deployments and helps configure them. Mixer helps make policy decisions. Envoy calls out to Mixer at request time. Pilot also controls the deployment of all the other pieces that Envoy uses to secure traffic.
An excellent blog post ion this topic is available on the Envoy website.
Using a service mesh, you will be able to use
- Intelligent Routing and Load-Balancing
- A/B Tests
- Smarter Canary Releases
- Chaos: Fault Injection
- Resilience: Circuit Breakers with Pool Ejection
- Observability: Metrics and Tracing
- Fleet wide policy enforcement without changing any code.
The presentation can be found here. The workshop can be found here. If you don’t have a Kubernetes, OpenShift or Minishift environment available, you can use the OpenShift learning platform although that approach hides a lot of technical complexity. If you are interested in service meshes, I recommend doing the workshop. It provides a lot of information in an attractive and easy consumeable format.