The Serverless Cloud
In recent years, the uprise of the cloud has brought us a lot of new and disruptive technologies. Everybody is talking about SaaS, PaaS, IaaS and other sorts of aaS. In 2014, Amazon launched AWS Lambda as the pinnacle of the cloud computing. It allows developers to focus on code, without spending time on managing servers.
Part 1
What?
While Microservices have been reigning the Cloud landscape for a couple of years, today the Serverless movement is one of the hottest trends in the industry. Historically, software developers have been pretty bad at naming things and Serverless is no exception. Disregarding what the name suggests, Serverless does not imply the complete absence of servers. It implies that developers who are using the Serverless architectural style, are not responsible for managing or provisioning the servers themselves, but use a vendor-supplied Cloud solution. Serverless means less worrying about servers. Although in the future, it might be possible to install this kind of service on-premise, for example with the open-source IBM OpenWhisk implementation.
In regard to this, the definition FaaS: Functions as a Service makes a lot more sense. Functions are short-lived pieces of runtime functionality that don’t need a server that’s always running. Strictly speaking a function can have a longer execution time, but most FaaS providers will currently limit the allowed computation time. When an application calls a function (eg. a calculation algorithm), this function gets instantiated on request. When it’s finished, it gets destroyed. This leads to a shorter “running” time and thus a significant financial advantage. As an example, you can find the AWS Lambda pricing here. FaaS functions are also a great match for event-driven behaviour: when an event is dispatched, the function can be started instantly and ran only for the needed time. A Serverless application is a composition of event chaining. This makes the Serverless style a natural match for API Economy.
As a result of being runtime components, FaaS functions are stateless and need to rely on a database (or file system) to store state. Being stateless and short-lived naturally lead to extreme horizontal scaling opportunities and all major FaaS providers support these.
NoOps
NoOps (No Operations) is the concept that an IT environment can become so automated and abstracted from the underlying infrastructure that there is no need for a dedicated team to manage software in-house. NoOps isn’t a new concept as this article from 2011 proves. When Serverless started gaining popularity, some people claimed there was no longer a need for Operations. Since we already established that Serverless doesn’t mean no servers, it’s obvious it also doesn’t mean No Operations. It might mean that Operations gets outsourced to a team with specialised skills, but we are still going to need: monitoring, security, remote debugging, … I am curious to see the impact on current DevOps teams though. A very interesting article on the NoOps topic, can be found over here.
AWS
AWS Lambda
AWS Lambda was the first major platform to support FaaS functions, running on the AWS infrastructure. Currently AWS Lambda supports three languages: Node.js, Java, and Python. AWS Lambda can be used both for synchronous and asynchronous services.
Currently the tooling for AWS Lambda is still relatively immature, but this is changing rapidly. At the time of writing, the AWS Lambda console offers the possibility to create a Lambda using blueprints. This is already easier than setting up a lambda by hand (using a ZIP-file). Blueprints are sample configurations of event sources and Lambda functions. Currently 45 blueprints are available. To give a short introduction, we’ll select the hello-world blueprint. This blueprint generates a very simple NodeJS function:
'use strict';
console.log('Loading function');
exports.handler = (event, context, callback) => {
console.log('value1 =', event.key1);
console.log('value2 =', event.key2);
console.log('value3 =', event.key3);
callback(null, event.key1);
};
After creating this function, it can be immediately be tested from the console, using a test event. If we want to call this function synchronously, we need to create an API endpoint with the AWS API Gateway. The API Gateway creates API’s that acts as a “front door” to your functions. To make this work with the events in our hello-world example, we need to select the resources of our API:
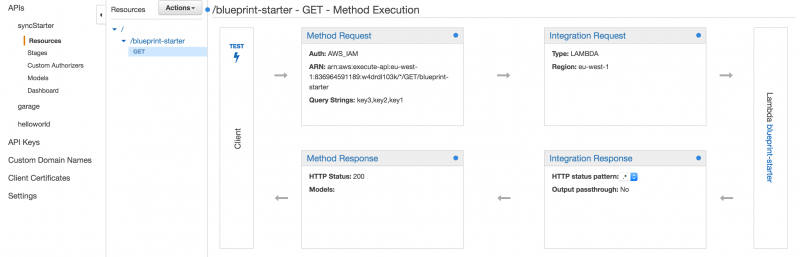
In Integration Request, we add a body mapping template of type application/json with the following template:
{
"key3": "$input.params('key3')",
"key2": "$input.params('key2')",
"key1": "$input.params('key1')"
}
In ‘Method request’ we add 3 URL String query parameters: key1, key2 and key3. If we then redeploy our API, hitting the Test button gives us an input form to add the 3 query parameters and the function is executed successfully:
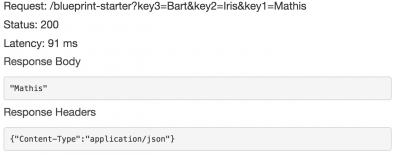
If you want to test this directly from a browser, you will need to change the Auth to NONE in the ‘Method request’ and do a new deploy of the API. The URL itself can be found in the ‘stage’-menu.
This example obviously is not very interesting, so let’s try another blueprint: microservice-http-endpoint. This will generate a CRUD backend, using DynamoDB with a RESTful API endpoint. The code generated, covers all common use-cases:
'use strict';
letdoc = require('dynamodb-doc');
letdynamo = newdoc.DynamoDB();
exports.handler = (event, context, callback) => {
const operation = event.operation;
if(event.tableName) {
event.payload.TableName = event.tableName;
}
switch(operation) {
case'create':
dynamo.putItem(event.payload, callback);
break;
case'read':
dynamo.getItem(event.payload, callback);
break;
case'update':
dynamo.updateItem(event.payload, callback);
break;
case'delete':
dynamo.deleteItem(event.payload, callback);
break;
case'list':
dynamo.scan(event.payload, callback);
break;
case'echo':
callback(null, event.payload);
break;
case'ping':
callback(null, 'pong');
break;
default:
callback(newError(`Unrecognized operation "${operation}"`));
}
};
Obviously you will need a DynamoDB instance with some data in it:
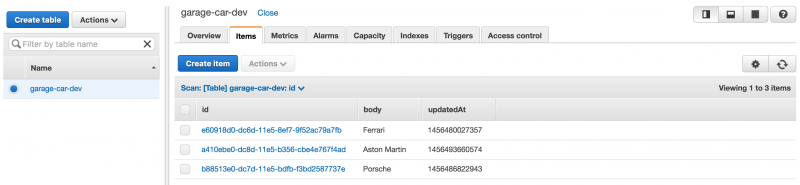
You can reference your new table, from your lambda, using the following event:
{
"tableName": "garage-car-dev",
"operation": "list",
"payload": { }
}
The only difficult part remaining, is finding out the required payload for the different operations :) This is a good start for creating new records:
{
"operation": "create",
"tableName": "garage-car-dev",
"payload": {
"Item": {
"id": "1980b61a-f5d7-46e8-b62a-0bbb91e20706",
"body": "Lamborghini",
"updatedAt": "1467559284484"
}
}
}
The blueprint also generates an API in the API Gateway that we can invoke with the above events as body mapping template in integration request of the method execution, just like the first example.
Serverless Framework
While the above approach works as expected, it’s quite cumbersome to get your first function working. Especially since we didn’t write any actual code in the previous examples. Luckily the Serverless Framework (formerly JAWS) is here to make our lives easier. Currently the Serverless Framework only supports AWS Lambda, but support for other IaaS providers is coming. A pull-request for Microsoft Azure already exists and other providers are also working on an implementation. Vendor-neutral FaaS would be a true game-changer!
One problem with FaaS, is the (deliberate) mismatch between runtime unit and deploy unit. This is also true for other architectural patterns. It should be possible to deploy one specific function, but often functions will hang out in groups. I’d prefer to deploy a group of functions in one go, when it makes sense, eg. different CRUD operations on the same resource. This way, we benefit from the advantages of functions (scalability, cost, service independence, …) but also ease deployment. This is a key feature of the Serverless Framework.

On June 29th, Serverless V1.0-alpha1 was announced. New Alphas and Betas will be released on a regular basis. Currently the documentation can only be found in their v1.0 branch on GitHub. Serverless V1.0 introduces the “Serverless Service” concept, which is a group of functions with their specific resource requirements. In essence Serverless V1.0 is a powerful and easy to use CLI to create, deploy and invoke functions. Serverless V1.0 uses AWS CloudFormation to create AWS resources. It uses the default AWS profile for access to your AWS account. Creating, deploying and invoking a “Hello World” NodeJS function with Serverless is as easy as:
serverless create --name cars --provider aws
serverless deploy
serverless invoke --function hello --path data.json
This generates the following lambda:
'use strict';
module.exports.hello = (event, context, cb) => cb(null,
{ message: 'Go Serverless v1.0! Your function executed successfully!', event }
);
The current version of the Serverless Framework (unfortunately) doesn’t use the region from the AWS config, so you might need to look for your function in a different region.
Adding an API Gateway endpoint, is also very easy and can be done by adding this http-event:
events:
- http:
path: greet
method: get
The actual URL can be found in the API Gateway in the stages section, as we saw before.
Part 2
In the first part of these article, I introduced the Serverless architectural style and focused on “market maker” AWS Lambda and on the Serverless Framework. In this part, I want to focus on other Faas providers.
Auth0 Webtask
Compared to giants such as Amazon, Google, Microsoft and IBM, Auth0 is a rather small player. However acknowledging their experience with BaaS (Backend as a Service), FaaS is a logical choice for them. Currently Webtask only supports NodeJS.
The recommended way of using webtask is through the wt command line interface. Auth0 has put the focus on easy of use. This is really visible by looking at their 30 second example. The wt create command wil generate a function (a webtask) and will automatically return an HTTP endpoint, supporting URL query parameters. Every query parameter is available in your webtask in the form of context.data JavaScript object. With AWS Lambda you need to configure these in the AWS API Gateway, which is both tedious and time-consuming.
A very interesting feature of Webtask is the availability of built-in storage. Webtask code can store a single JSON document up to 500KB in size. This data can be stored with ctx.storage.set and retrieved with ctx.storage.get. While I don’t believe your function will often need this, it’s a very nice option.
This small example (using Lodash), shows a webtask using a query parameter and built-in storage.
module.exports = function (ctx, cb) {
var name = ctx.query.name;
if(name) {
ctx.storage.get(function(err, data){
if(err) cb(err);
data = data || [];
if(_.indexOf(data, name) === -1 ){
data.push(name);
ctx.storage.set(data, function(err){
if(err){
cb(err);
} else {
cb(null, data);
}
})
} else {
cb(null, data);
}
})
} else {
cb(null, "422");
}
}
Deploying this webtask, using the CLI:
Webtask created
You can access your webtask at the following url:
https://webtask.it.auth0.com/api/run/wt-<your username>-0/query_store?webtask_no_cache=1
Another way to access your webtask is as a CRON job, using the wt cron command or as a web hook.
Contrary to AWS Lambda, you don’t need to bundle the NodeJS modules you want to use. The list of supported modules is available here. An option to bundle other modules is also available. Another difference is the use of query parameters.
Not surprisingly, Webtask can be integrated with Auth0 for authentication and authorization.
Google Cloud Functions
Google Cloud Functions (GCF) was released early 2016 and is currently in private alpha. Being in private alpha not only means that you specifically need to request access to use the GCF API, but also that you’re limited in sharing information. While this is obviously very unfortunate, it also means that Google is very serious about releasing a complete product. The activity in their (again private) Google Group proves this.
Like its competitors, Cloud Functions can be triggered asynchronously by events (from Cloud Pub/Sub and Cloud Storage) or invoked synchronously via HTTPS. Currently GCF only supports NodeJS. Tutorials on common use-cases are available in their documentation. To build functions with GCF, you will first need to download and install the Google Cloud SDK. With the SDK installed, you can create your initial function (replace datastore_gcf with your own staging bucket name):
$ gsutil mb gs://datastore_gcf
From the (very useful) (unofficial) GCF recipes by Jason Polites (Product Manager, GCP), we cloned the datastore example that will persist data to a Google Coud Datastore.
From this repository, we deployed 2 functions ‘ds-get’ and ‘ds-set’ by executing:
$ gcloud alpha functions deploy ds-set --bucket datastore_gcf --trigger-http --entry-point set
The names of the deployed functions, need to be exported in the Node.js module. These functions can be called with:
$ gcloud alpha functions call ds-get --data '{"kind": "test", "key": "kid"}'
or via the Cloud Functions Console.
Your newly added data is also available in the Datastore Entities after selecting a project on the top. After executing a couple of functions, you can also find some metrics of your function (number of calls, execution time, …)
Other arguments for the deploy command are listed in the reference documentation. These steps are also available in the Cloud Platform Console.
After deployment, your webtrigger URL will be displayed similar to Webtask.
Although much information on Google Cloud Functions is not (publicly) available yet, Google is well on its way to become a serious FaaS provider.
Azure Functions
Similar to Google Cloud Functions, Microsoft Azure Functions is currently in preview stage, meaning it’s not (yet) meant to be used in a production environment. Azure Cloud Functions (ACF) support a variety of languages such as NodeJS, C#, Python, and PHP.
Today, it can be used for these common cases:
- Events triggered by other Azure services
- Events triggered by SaaS services (not limited to Microsoft)
- Synchronous requests
- WebHooks
- Timer based processing (CRON)
creating quite a large number of possibilities.
Azure Functions are grouped in App Services. This is quite different from AWS Lambda, where the functions are organised independently. Hardware resources are allocated to an App Service and not directly to an Azure Function. It’s important to select a dynamic App Service if you’re aiming for “pay-per-execution”.
When creating a new function, you can start from different templates. This can be compared to the blueprints from AWS Lambda. Currently 44 templates are available (but some are very similar). When selecting HttpTrigger for example, Azure Functions will generate a function that is able to use all query parameters passed to the function, similar to Webtask. This short video demonstrates this use case.
In the example below, an Azure Cloud Function will store entities in a Storage Table when it receives an HTTP request:
function.json:
"bindings": [
{
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"post"
],
"authLevel": "function"
},
{
"type": "http",
"direction": "out",
"name": "res"
},
{
"type": "table",
"name": "outTable",
"tableName": "entities",
"partitionKey": "functions",
"rowKey": "%rand-guid%",
"connection": "YOUR_STORAGE",
"direction": "out"
}
],
"disabled": false
}
index.js:
var statusCode = 400;
var responseBody = "Invalid request object";
if (typeof req.body != 'undefined' && typeof req.body == 'object') {
statusCode = 201;
context.bindings.outTable = req.body;
responseBody = "Table Storage Created";
}
context.res = {
status: statusCode,
body: responseBody
};
context.done();
};
To retrieve the added entities:
functions.json:
"bindings": [
{
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get"
],
"authLevel": "function"
},
{
"type": "http",
"direction": "out",
"name": "res"
},
{
"type": "table",
"name": "inTable",
"tableName": "entities",
"connection": "YOUR_STORAGE",
"direction": "in"
}
],
"disabled": false
index.js:
context.log("Retrieved records:", intable);
context.res = {
status: 200,
body: intable
};
context.done();
};
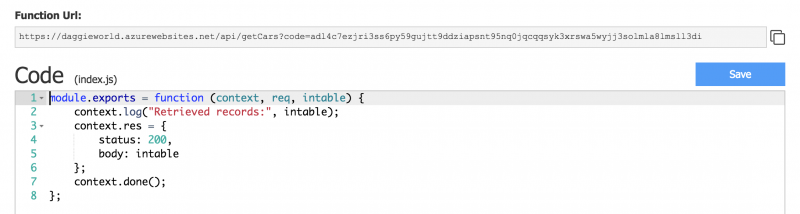
What immediately struck me was the quality of their documentation (videos, tours, quickstarts, templates, …) and the user experience from the Azure Portal. The portal can be a little slow sometimes, but the experience is miles ahead of what Amazon and Google are offering. Azure Functions is open source and available on GitHub.
Azure Functions will soon be supported by the Serverless Framework, which is a big step towards vendor-neutral FaaS.
IBM Bluemix OpenWhisk
Bluemix OpenWhisk is also an open source service and currently supports NodeJS and Swift. Contrary to other FaaS providers, IBM emphasises on container integration. When an event or an API call invokes an action, OpenWhisk creates a container to run the action in a runtime appropriate to the programming language used. You can even create Docker functions (called actions in OpenWhisk) allowing you to build in any language. OpenWhisk can also run locally on your own hardware, which no other provider currently offers. IBM is very open about this and even provides guidelines on how this can be achieved.
As expected, the documentation has a getting started guide to build and run a Hello World action. While working with the CLI works as advertised, it quickly becomes quite cumbersome, especially when integrating with other Bluemix services. After executing your first OpenWhisk function, you can see some metrics in the (pretty) OpenWhisk dashboard. The OpenWhisk dashboard will show all invoked actions, also from actions you didn’t implement yourself. For example when using existing packages.

What’s even more impressive is the Openwhisk Editor. This editor only lists the actions you created yourself.
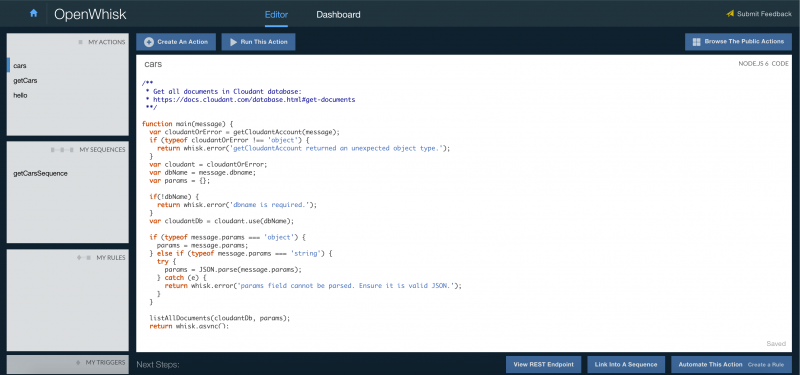
As you can see from the screenshot, you immediately get links to the REST Endpoint.
Conclusion
Currently it’s too soon to draw any conclusions. These services are constantly changing. What is obvious, is that all major cloud providers want to make sure that they don’t miss the FaaS opportunity. Cloud providers create value by integrating FaaS services with their other offerings. This confirms the value of a Serverless Cloud. The current FaaS solutions have a lot of similar characteristics and choosing one, will likely depend on what other services you already use (or want to use) from a certain provider. It’s important to know the environment your FaaS code lives in and the services available to it. In this phase available documentation also is crucial.
Obviously, this high-level introduction doesn’t list all the differences or similarities, but it offers a nice starting point to experience the FaaS (r)evolution first-hand.
Part 3
In the first part of this article, I introduced the Serverless architectural style. In the second part, I compared all major serverless providers. In this third and last part, I would like to look at serverless as an enabler of collaborative economy.
Collaborative Economy
What is collaborative ecomomy?
Benita Matofska: The Sharing Economy is a socio-economic ecosystem built around the sharing of human, physical and intellectual resources. It includes the shared creation, production, distribution, trade and consumption of goods and services by different people and organisations.
The last part of Benita’s quote: shared creation, production .. of services by different people and organisations makes a very nice use-case for the serverless style of building applications.
Your data
In this day and age, all companies have become IT companies, meaning a lot of data is gathered and stored somewhere. Often the usage of the available data changes over time. If data is not used for the benefit of the enterprise or its employees, does it still hold value? Wouldn’t it be great if we could turn cost into profit?
Thanks to its cost model (pay per execution), its focus on scalability (no risk of overprovisioning) and resilience, serverless enables companies to experiment with exposing their data:
- Offering an API for others to consume
- Enriching existing API’s with their data
- …
Your ideas
Serverless also makes a lot of sense for companies that don’t want to expose their data, but have great or new ideas on how to use others data:
- Combining data from multiple providers
- Filtering and transforming data
- New business cases beyond the scope of the original API
- …
Example
I implemented a small and simple application that will consume data from different serverless cloud providers. Every “hop” in the system will parse its input and add some new data.
Component diagram
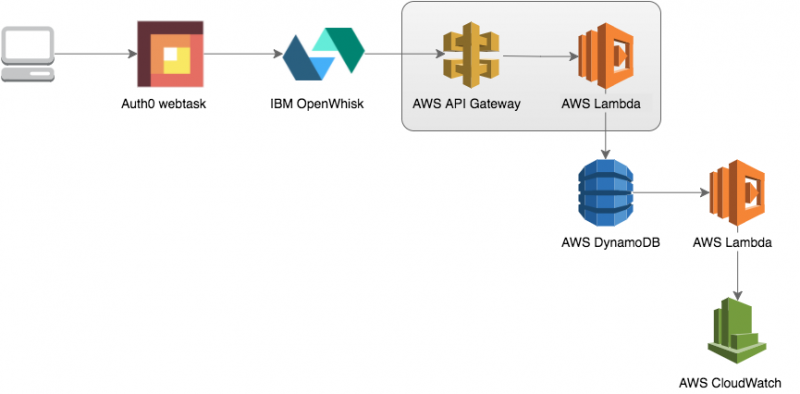
Description
Any client can post a JSON to the first function, made with Auth0 webtask. The body of the post request is simple:
{"temp":"42"}
The WebTask will parse that input, add some input of its own and POST request to an IBM OpenWhisk action. The body of this POST request:
{
"hops": [
{
"provider": "Auth 0 Webtask",
"start": "2016-08-24T20:32:03.629Z",
"temperature": "42",
"stop": "2016-08-24T20:32:03.629Z"
}
]
}
To continue the chain, IBM OpenWhisk will POST the parsed JSON to a function on the AWS Lambda platform after adding a new “hop”:
{
"hops": [
{
"provider": "Auth 0 Webtask",
"start": "2016-08-26T18:38:25.021Z",
"temperature": "44",
"stop": "2016-08-26T18:38:25.021Z"
},
{
"provider": "IBM OpenWhisk",
"start": "2016-08-26T18:38:35.024Z",
"temperature": "42",
"stop": "2016-08-26T18:38:35.024Z"
}
]
}
The Lambda, created with Serverless V1.0 Beta 2 will parse the input again and create items in an AWS DynamoDB:
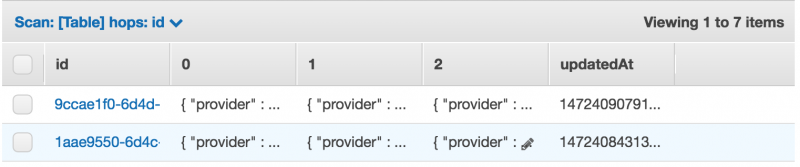
The AWS DynamoDB table will stream events to another AWS Lambda that will log the content of the event to the logs of AWS CloudWatch:

The source code of all these components is available on GitHub.
Best practice
Obviously I wouldn’t recommend anyone to use a different cloud provider for every function. Choosing the right one will depend on your specific needs, goals and current cloud landscape. In previous parts of this article, you may find some tips on how to make a reasoned choice.
Final note
This article was originally posted in three parts on the JAX London blog and is also available in German.